
To evaluate the performance of the participating methods in terms of the classification accuracy, the results provided by the participants will be compared with the ground truth information and several accuracy metrics will be computed. A confusion matrix is computed to get an insight into the classification accuracy. From the computed confusion matrix, several per-pixel classification accuracy metrics, including precision (P), recall (R), classification accuracy rate (CA) and F-measure (F) will be performed.
- The precision metric (P) corresponds to the proportion of the predicted cases that are correctly matched to the benchmark classifications. It is considered as a means of assessing the classification.
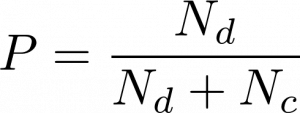
- The recall measure (R) indicates the proportion of real cases that are correctly predicted. It is considered a way to improve the classification.
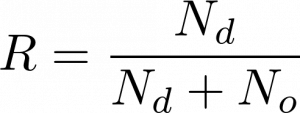
- The classification accuracy rate (CA) metric corresponds to the ratio of the true classified predicted pixels and the total number of pixels.
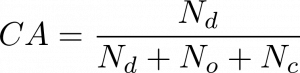
- The F-measure (F) can be computed as a score resulting from the combination of the P and the R accuracies by using a harmonic mean. It assesses both the homogeneity and the completeness criteria of a clustering result.
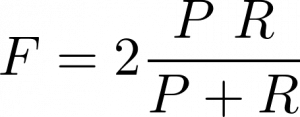
where Nd denotes the number of the M diagonal elements which represent the all correctly assigned samples to theirs classes.
No denotes the number of the M elements, excluding those of its diagonal, along a column (clustering outcomes) correspond to omission samples.
Nc represents the number of the M elements, excluding those of its diagonal, along a row (ground-truth classes) correspond to commission samples.
These classical per-pixel classification accuracy metrics will be computed for each content type independently for each book. This will allow determining whether a participating method behaves uniformly among all the books or if, conversely, it achieves a different level of performance for different books. On the other hand, computing the classification accuracy metrics for each content type will allow to identify methods that have high performance for specific content types (or for one particular book), even if their overall performance is not so high.
It is worth noting that computing the overall classification accuracy metrics is not a good way for evaluating the performance of a participating method as it would mainly measure the performance on the majority classes due to the imbalanced headcounts between classes.
The performance measures will be computed for the two challenges (text/graphic separation and font discrimination) at pixel level. Both the performance measures for each book of the evaluation dataset and the overall performance will be calculated.
Download links
The evaluation tools of the HBA contest are available for download from the following link: